Write the business logic of our test and insert TestNG annotations in the code.
Add the information about our test (e.g. the class name, the groups you wish to run, etc…) in a testng.xml or build.xml file. In this post we will configure using testing.xml file.
Run TestNG using Command Line, Ant, IDEs. We will be executing our test using Eclipse IDE.
Let’s start with our first TestNG script. We will use the same Java Project ‘FrameworkDesign’ that we created in Keyword Driven Framework Development…
First step is to add the TestNG libraries into our project. Right click on the project ‘FrameworkDesign’ and click Properties -> Java Build Path -> Add Library.
Add TestNG Library
In Add Library window, select TestNG and click on Next. Click on Finish to add the TestNG Library. Click OK to close the Properties window.
Select TestNG
Once the above steps are completed, we will see TestNG Library added to our Java Project.
TestNG Library added
Test Case:
Let’s create our first test case using TestNG. This time we will use a different test website ‘http://www.newtours.demoaut.com‘ for creating our test cases.
First Test Case:Navigate to New Tours application and perform successful login. Second Test Case:Navigate to New Tours application and perform successful registration.
We will use all the annotations in our script just to give an understanding on the workflow of a TestNG script. We will also use Data Providers for test data input.
Right click on ‘com.selenium.testcase’ package inside ‘FrameworkDesign’ Java project and select TestNG -> Create TestNG Class as shown below.
Create TestNG Class
Give Class Name as ‘FirstTestNScript’ and select all annotations. This is just for learning purpose as you can create a TestNG script with out selecting any of the annotations selected below. However in that case, the TestNG script will have ‘@Test‘ annotation as default. Remember that TestNG class don’t have static main methods so method with annotations will start the execution.
New TestNG class
As we click Finish, a new class ‘FirstTestNScript’ is created with all the annotations and corresponding methods. To begin with we will just add ‘System.out.println’ code in all methods to print different messages in the console. This will give an idea on the workflow of the TestNG class.
package com.selenium.testcase;
import org.testng.annotations.Test;
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.AfterMethod;
import org.testng.annotations.DataProvider;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeSuite;
import org.testng.annotations.AfterSuite;
public class FirstTestNScript {
@Test(dataProvider = "dp")
public void f(Integer n, String s) {
System.out.println("This is Test Method");
}
@BeforeMethod
public void beforeMethod() {
System.out.println("This is Before Method");
}
@AfterMethod
public void afterMethod() {
System.out.println("This is After Method");
}
@DataProvider
public Object[][] dp() {
return new Object[][] { new Object[] { 1, "a" }, new Object[] { 2, "b" }, };
}
@BeforeClass
public void beforeClass() {
System.out.println("This is Before Class");
}
@AfterClass
public void afterClass() {
System.out.println("This is After Class");
}
@BeforeTest
public void beforeTest() {
System.out.println("This is Before Test");
}
@AfterTest
public void afterTest() {
System.out.println("This is After Test");
}
@BeforeSuite
public void beforeSuite() {
System.out.println("This is Before Suite");
}
@AfterSuite
public void afterSuite() {
System.out.println("This is After Suite");
}
}
To execute our TestNG script, right click on ‘FirstTestNScript’ and click TestNG Test. The execution will be completed in no time and it will print some messages in the console. If we look closely on the console output, we can see that the messages are printed in the console in a particular order.
Test Output
From the test output we can easily conclude that ‘@Before/AfterSuite’ annotations are the very first and the last ones to be executed. Then ‘@Before/AfterTest’, followed by ‘@Before/AfterClass’. The ‘@Before/AfterMethod’ has executed twice alone with ‘@Test’ method. This is because the data provider ‘dp‘ has two sets of test data ({{ 1, “a” }, {2, “b”}}) and ‘@Test’ method executes twice using different set of test data from the data provider. Since ‘@Test’ is executed twice, so do ‘@Before/AfterMethod’ for each ‘@Test’ method.
If we refresh our Java Project, a new folder named ‘test-output‘ is created with many HTML reports. To view an HTML file, right click on the file and click Open With -> Web Browser. This reports are generated by TestNG once the execution is completed.
View TestNG reports
In our next post we will continue to update this ‘FirstTestNScript’ class with the logic of two test cases mentioned above, followed by test execution and analysis of TestNG reports. We will also learn to configure our TestNG script using testing.xml file. Till then, Happy Learning!
Additional Information:
What is Data Provided in TestNG?
‘@DataProvider‘ marks a method as supplying data for a test method. The annotated method must return an Object[][] (2D Array) where each Object[] can be assigned the parameter list of the test method. In the above example we are passing two sets of data. This means the ‘@Test‘ method (which has the test case logic) will be executed twice, each with one set of test data. As we move on to next post, the use of Data Provider will be more understandable.
Till now we have created our executable test scripts inside main methods in Java classes. However this approach has many limitations as they always require human intervention with the execution. To overcome these shortcomings, there are tools like TestNG, JUnit that not only help us with organizing and grouping of our tests but also help us with reporting of test results. In simple words, both these tools has many advantages that will make our tests more easier to develop and maintain. In this post we will be focusing on TestNG as it is an extension of JUnit.
TestNG Introduction:
TestNG is an open source automated testing tool available in market. It is similar to JUnit in design but it has more advantages over JUnit. One of the main reason of using TestNG or JUnit is that we don’t have to use static main methods in our test scripts. Some other advantages are:
Selenium WebDriver has no support for test reports. However with TestNG/JUnit we can generate reports in readable formats.
TestNG/JUnit has different annotation like ‘@BeforeClass’, ‘@AfterClass’, ‘@Test’ etc. These annotations help us in configuring our test cases. Also we can pass additional parameters using annotations.
Any uncaught exceptions can be handled by TestNG/JUnit without terminating the test prematurely. These exceptions are reported as failed steps in the report.
In TestNG, we can use the following annotations for configuring our test case:
@BeforeSuite: The annotated method will be run before all tests in this suite have run. @AfterSuite: The annotated method will be run after all tests in this suite have run. @BeforeTest: The annotated method will be run before any test method belonging to the classes inside the <test> tag is run. @AfterTest: The annotated method will be run after all the test methods belonging to the classes inside the <test> tag have run. @BeforeGroups: The list of groups that this configuration method will run before. This method is guaranteed to run shortly before the first test method that belongs to any of these groups is invoked. @AfterGroups: The list of groups that this configuration method will run after. This method is guaranteed to run shortly after the last test method that belongs to any of these groups is invoked. @BeforeClass: The annotated method will be run before the first test method in the current class is invoked. @AfterClass: The annotated method will be run after all the test methods in the current class have been run. @BeforeMethod: The annotated method will be run before each test method. @AfterMethod: The annotated method will be run after each test method. @DataProvider: Marks a method as supplying data for a test method. The annotated method must return an Object[][] where each Object[] can be assigned the parameter list of the test method. The @Test method that wants to receive data from this DataProvider needs to use a dataProvider name equals to the name of this annotation. @Test: Marks a class or a method as part of the test.
The complete list of annotations and their descriptions are mentioned in below link: TestNG Annotations
TestNG Installation:
Now that we had some introduction on the TestNG, lets install in our Eclipse.
Launch the Eclipse IDE and click Help -> Install New Software option.
Click on Add button to Add Repository.
Click Add to Add Repository
Enter following details: Name: ‘TestNG’, Location: ‘http://beust.com/eclipse’. Click OK to close the window.
Add a Repository
Select ‘TestNG’ option and click Next.
Select TestNG
Click on Next and accept the license agreement and hit Finish to complete the installation process. Once the installation is complete, we need to restart the Eclipse.
To verify if the installation was successful or not, right click on a project to view the below options.
TestNG options
With this we completed the TestNG installation in Eclipse. In our next post we will focus on creation and execution of TestNG tests and then view the test results in TestNG reports.
Keyword Driven is more or less similar to Data Driven approach however in this case we will create test steps in an Excel sheet. Our test case will use the test steps and keywords like ‘openBrowser’, ‘navigate’ etc., from the Excel sheet and perform set of actions in a web page. A separate class file will have the definitions for these keywords. Now let’s create a sample framework based on what we discussed. We will use the same project from our last post but will rename the project to ‘FrameworkDesign’. You can easily a rename a project in Eclipse by clicking ‘F2’ to edit.
The first step is to create our test steps in an Excel sheet and name it as ‘KeywordAction.xlsx’. We will place this Excel sheet inside the ‘com.selenium.data’ package. We can either do it by drag or drop or else you can go to the project location and directly paste it in ‘src/com/selenium/actions’ folder. ‘com.selenium.data’ package was already created in our last post.
Test Steps
Right click on the ‘src‘ folder and click New -> Package. Name the package as ‘com.selenium.actions’ and click Finish to close the window.
Right click on ‘com.selenium.actions’ package and click New -> Class. Name the class as ‘Actions’. This class will contain definition of all keywords (Actions column) that we used in ‘KeywordAction.xlsx’ Excel. Copy the below code and paste into ‘Actions’ class. All the keywords (for example openBrowser, navigateURL, enterText etc) used in our Excel sheet are static methods in ‘Actions’ class.
package com.selenium.actions;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class Actions {
public static WebDriver driver;
// Open Browser
public static void openBrowser() {
System.setProperty("webdriver.chrome.driver", System.getProperty("user.dir") + "/Chrome/chromedriver");
driver = new ChromeDriver();
}
// Navigate to URL
public static void navigateURL() {
driver.get("http://www.google.com");
driver.manage().window().maximize();
}
// Enter text in text box
public static void enterText(String inputText) {
// Relative XPath for the text box
driver.findElement(By.xpath("//input[@id='lst-ib']")).sendKeys(inputText);
}
// Click Search icon
public static void clickButton() {
/* Find the Web Element Search icon. After finding, click the search icon */
driver.findElement(By.id("_fZl")).click();
}
// Click URL
public static void clickLink(String linkText) throws InterruptedException {
// Wait for page to load
Thread.sleep(5000);
// Enter text from test data Excel row 1 column 4
driver.findElement(By.partialLinkText(linkText)).click();
}
// Title verification
public static boolean verifyTitle(String titleText) throws InterruptedException {
// Wait for page to load
Thread.sleep(5000);
String title = driver.getTitle();
// Title verification. The third link is Wikipedia link
if (title.equals(titleText)) {
System.out.println("TITLE VERIFIED.");
System.out.println("TEST CASE PASSED");
return true;
} else {
System.out.println("TITLE NOT VERIFIED.");
return false;
}
}
// Close the browser
public static void closeBrowser() {
// Close and quit the driver to close the Browser
driver.close();
driver.quit();
}
}
Next step is to create the test case. We will use the test steps from ‘KeywordAction.xlsx’ Excel. Right click on ‘com.selenium.testcase’ package, that we created in our last project and click New -> Class to add a new class file. Name the class file as ‘TC_KeySeleniumSearch’. Copy the below code into ‘TC_KeySeleniumSearch’.
package com.selenium.testcase;
import com.selenium.actions.Actions;
import com.selenium.utils.Constants;
import com.selenium.utils.ExcelUtil;
public class TC_KeySeleniumSearch {
public static void main(String[] args) throws Exception {
// Set the path to KeywordAction.xlsx Excel sheet
String sPath = System.getProperty("user.dir") + "/src/com/selenium/data/KeywordAction.xlsx";
/* Set the Excel path with the sheet name mentioned in Constants class */
ExcelUtil.setExcelFile(sPath, Constants.SHEETNAME);
/*
* We are looping all the 8 rows in Excel starting from row 1. Remember row 0 is the header in Excel sheet
*/
for (int rowNumber = 1; rowNumber < 8; rowNumber++) {
// This is to take the keywords from 3rd column
String sActionKeyword = ExcelUtil.getCellData(rowNumber, 3);
if (sActionKeyword.equals("openBrowser")) {
/* This will execute if Excel cell has 'openBrowser' */
Actions.openBrowser();
} else if (sActionKeyword.equals("navigateURL")) {
/* This will execute if Excel cell has 'navigateURL' */
Actions.navigateURL("http://www.google.com");
} else if (sActionKeyword.equals("enterText")) {
/* This will execute if Excel cell has 'enterText' */
Actions.enterText("Selenium");
} else if (sActionKeyword.equals("clickButton")) {
/* This will execute if Excel cell has 'clickButton' */
Actions.clickButton();
} else if (sActionKeyword.equals("clickLink")) {
/* This will execute if Excel cell has 'clickLink' */
Actions.clickLink("Wikipedia");
} else if (sActionKeyword.equals("verifyTitle")) {
/* This will execute if Excel cell has 'verifyTitle' */
Actions.verifyTitle("Selenium (software) - Wikipedia");
} else if (sActionKeyword.equals("closeBrowser")) {
/* This will execute if Excel cell has 'closeBrowser' */
Actions.closeBrowser();
}
}
}
}
The idea behind the Keyword Driven Framework is to have the test steps created in Excel. Each test step will have keywords to perform an action on our test website. This way the test cases becomes easily readable and maintainable.
Below screenshot shows the folder structure of our project.
Folder Structure
The next step is to execute our test case. Right click on ‘TC_KeySeleniumSearch’ and click Run As -> Java Application. Once the execution is successfuly completed, we can see below output in the console.
Console output
With this we came to end on the basics of Keyword Driven approach. This framework is similar to Data Driven one as both uses Apache POI jars. Please post your comments and let me know your thoughts…
In my last post I gave an introduction on Data Driven Framework. In this post we will mainly concentrate on developing a sample Data Driven Framework.
Launch Eclipse. Create a new Java Project by clicking on File -> New -> Java Project.
Give the project name as ‘DatadrivenFramework’ and click on Finish to close the window. Once the project is created, we will have ‘src‘ folder and ‘JRE System Library‘ by default.
Next step is to add the Selenium Jars. Right Click on the project name and click Properties. Click on Java Build Path -> Add External Jars. Go to the local folder where ‘selenium-server-standalone-3.0.1’ is saved. We will be using 3.0.1 version from our last project. Add the Jar and click OK to close the window. Once complete, we will see ‘Referenced Libraries‘ included in our project.
Next step is add the Chrome Driver. Right click on the project name and click New -> Folder. Give the folder name as ‘Chrome’ and click Finish to close the window. Now place the Chrome driver that we already downloaded in our last project into the ‘Chrome’ folder.
To work with input files like Excel, CSVs etc we need to download Apache POI jars and add them into our project.
Go to Google and type in ‘apache poi jar download’. Click on the first link ‘Apache POI – Download Release Artifacts’. URL: Apache POI
Click on the latest stable version. As of today Apache POI 3.15 is the stable version. Go to Binary Distribution section and click on the zip file to start the download.
Download the zip file into your local folder
Unzip the downloaded file. Now you have to add all the Jars into your project. To import the Jars, right click on the project name and click Properties. Click on Java Build Path -> Add External Jars. Go to the local folder where ‘poi-3.15’ is saved. Add all Jars in the ‘poi-3.15’ folder. Make sure to add the Jars in ‘lib’ and ‘ooxml-lib’ folders too. Click OK to close the window. The ‘Referenced Libraries‘ in the project will be updated with the Apache POI Jars.
The next step is to create the test data Excel Sheet. You can create one test data Excel sheet as shown below and save it as ‘TC_SearchSelenium.xlsx’. Apache POI works in MS Excel. It will not work for Mac Numbers. So even if you are working in Mac machine, make sure to have MS Excel installed.
Test Data creation in Excel
Right click on the project name and click New -> Folder. Give the folder name as ‘TestResults’ and click Finish to close the window. In this folder the test data Excel sheet with ‘PASS/FAIL’ result will be placed once the execution completes.
Now we need to create a new package inside the ‘src‘ folder of our project. Right click on the ‘src‘ folder and click New -> Package. Name the package as ‘com.selenium.data’ and click Finish to close the window.
We have to add the test data Excel into this package. You can do this by drag and drop or else you can copy the Excel and directly paste it into your Project/src/com/selenium/data folder.
Right click on the ‘src‘ folder and click New -> Package. Name the package as ‘com.selenium.utils’ and click Finish to close the window.
On the ‘com.selenium.utils’ package, right click on New -> Class to create a new class file. Name the class as ‘Constants’. Click Finish to create a new class. Copy the below code and paste it into the ‘Constants’ class file.
package com.selenium.utils;
public class Constants {
// TestResults folder location
public static final String PATH_RESULTS = System.getProperty("user.dir") + "/TestResults/";
// Test Data Excel location
public static final String PATH_DATA = System.getProperty("user.dir")
+ "/src/com/selenium/data/TC_SearchSelenium.xlsx";
// Test Data Excel Sheet name
public static final String SHEETNAME = "Sheet1";
// Test Data Excel File Name
public static final String FILE_NAME = "TC_SearchSelenium.xlsx";
}
On the ‘com.selenium.utils’ package, right click on New -> Class to create a new class file. Name the class as ‘ExcelUtil’. Click Finish to create a new class.
Copy the below code in to the ‘ExcelUtil’ class and save it.
package com.selenium.utils;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class ExcelUtil {
private static XSSFSheet excelWSheet;
private static XSSFWorkbook excelWBook;
private static XSSFCell cell;
private static XSSFRow row;
/*
* This method is to set the File path and to open the Excel file. Pass
* Excel Path and Sheet name as Arguments to this method
*/
public static void setExcelFile(String Path, String SheetName) throws Exception {
try {
// Open the Excel file
FileInputStream ExcelFile = new FileInputStream(Path);
// Access the Excel workbook
excelWBook = new XSSFWorkbook(ExcelFile);
// Access the Excel Sheet
excelWSheet = excelWBook.getSheet(SheetName);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* This method is to read the test data from the Excel cell. We are passing
* parameters as Row number and Column number
*/
public static String getCellData(int RowNum, int ColNum) throws Exception {
try {
// Access a particular cell in a sheet
cell = excelWSheet.getRow(RowNum).getCell(ColNum); String CellData = cell.getStringCellValue();
return CellData;
} catch (Exception e) {
return null;
}
}
/*
* This method is to write in the Excel cell. Passing Row number and Column
* number are the parameters
*/
public static void setCellData(String Result, int RowNum, int ColNum) throws Exception {
try {
cell = excelWSheet.getRow(RowNum).getCell(ColNum);
if (cell == null) {
cell = row.createCell(ColNum);cell.setCellValue(Result);
} else {
cell.setCellValue(Result);
}
// Update the Test Results folder with 'PASS/FAIL results'
FileOutputStream fileOut = new FileOutputStream(Constants.PATH_RESULTS + Constants.FILE_NAME);
excelWBook.write(fileOut);
fileOut.flush();
fileOut.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Next we will create our actual test case. We will take the same code from our first test case, however we will do some modification on the input parameters.
Right click on the ‘src‘ folder and click New -> Package. Name the package as ‘com.selenium.testcase’ and click Finish to close the window.
On the ‘com.selenium.testcase’ package, right click on New -> Class to create a new class file. Name the class as ‘TC_SeleniumSearch’. Click Finish to create a new class. Copy the below code and paste it into the ‘TC_SeleniumSearch’ class file.
package com.selenium.testcase;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import com.selenium.utils.Constants;
import com.selenium.utils.ExcelUtil;
public class TC_SeleniumSearch {
public static void main(String[] args) throws Exception {
// Setting System properties
System.setProperty("webdriver.chrome.driver", System.getProperty("user.dir") + "/Chrome/chromedriver");
// Initialize WebDriver
WebDriver driver = new ChromeDriver();
//Set the File path of our test data Excel
ExcelUtil.setExcelFile(Constants.PATH_DATA, Constants.SHEETNAME);
/* Navigate to Google Website. Test data taken from row 1 column 2 */
driver.get(ExcelUtil.getCellData(1, 2));
// Maximize browser window
driver.manage().window().maximize();
// Relative XPath for the text box
driver.findElement(By.xpath("//input[@id='lst-ib']")).sendKeys(ExcelUtil.getCellData(1, 3));
/* Find the Web Element Search icon. After finding, click the search icon */
driver.findElement(By.id("_fZl")).click();
/* Wait for page to load. Thread.sleep() throws InterruptedException */
Thread.sleep(5000);
//Enter text from test data Excel row 1 column 4
driver.findElement(By.partialLinkText(ExcelUtil.getCellData(1, 4))).click();
/* Wait for page to load. Thread.sleep() throws InterruptedException */
Thread.sleep(3000);
// Store the title in a variable
String title = driver.getTitle();
/* Title verification. Get text from test data Excel row 1 column 5 */
if (title.equals(ExcelUtil.getCellData(1, 5))) {
System.out.println("TITLE VERIFIED.");
/*Set the PASS result in test data Excel row 1 column 6 */
ExcelUtil.setCellData("PASS", 1, 6);
System.out.println("TEST CASE PASSED");
} else {
/*Set the FAIL result in test data Excel row 1 column 6 */
ExcelUtil.setCellData("FAIL", 1, 6);
System.out.println("TITLE NOT VERIFIED.");
}
// Close and quit the driver to close the Browser
driver.close();
driver.quit();
}
}
As you see in the above code, we have removed all the hard coded test data from our test case and instead gave a reference to the test data Excel sheet. Our test case became more maintainable with this approach and any further updates to test data is also simple.
The overall project structure will look like:
Project Structure
The final step is to execute our test case. Right click on “TC_SeleniumSearch” class and click Run As -> Java Application. As we progress with our execution we can see the all the input data is taken from our test data Excel sheet. Test Case execution successfully completes and we see the following output in the console.
Execution Passed
As we check the ‘TestResult’ folder, a new Excel sheet is placed with the test result. Open the Excel sheet and we can see the test results are updated with ‘PASS results’.
Test Results updated
With this we came to an end of our Data Driven Framework creation. You can modify this code to take the input of different browsers. For that you just need to update the “TC_SeleniumSearch” class file with ‘if-else’ logic.
Happy Learning and do share your comments!
Additional Information:
If you refer to ‘ExcelUtil’ class, we have used instances of XSSFWorkbook, XSSFSheet etc to access a particular cell in an Excel. Apache POI provides documentation on all of these classes. You can visit the below URL for more details:
Framework development is an integral part in automation testing and there are many advantages when we shift to a framework. Without using a framework all our code and data will be in the same place and thus restricting us from code reusability and easy maintenance.
We will briefly go through each of the frameworks currently been used:
Data Driven Framework:
In Data Driven framework all our test data is stored in from some external files like Excel, CSV, XML or Database tables. This way we can run our automation scripts multiple times using different test data stored in any of the input files. In our last example, Second Test Case, we hard coded the test data like ‘Selenium’. What if someday we want to modify our test case to search for a different text? We will have to go to each of the test cases to update the input value. We can avoid this situation if we store the input value in any of the files mentioned and refer that file to our test case. This will resolve our issue to some extent. We will do a detailed analysis on this topic in our next post.
Keyword Driven Framework:
In Keyword Driver Framework all the instructions or steps are written in an Excel sheet. For example in our Second Test Case, we have the first test step to open the browser. Corresponding to this step, our Excel sheet will also have the step ‘openBrowser’. Code for this ‘openBrowser’ will be written in a separate class file. The idea behind the Keyword Driven approach is to have all the instructions written in an Excel or in other words to have the test cases created in Excel and then execute these instructions. This way we can easily manage the test case by updating the Excel. For better understanding of the framework, we will do a detailed analysis in upcoming posts.
Page Object Model:
Page Object Model or POM is a concept where we will create separate class files for each page of our test application. This Page class will have all elements associated with that web page and will also contain methods which perform operations on those elements. If we take the case of our first test case, there will be one page class for Google Search page. This class will contain all elements like the search text box, search button etc. The class will also have a search method which will actually click the search icon for doing the search. As we move on to a different page, we will have a new page class with all elements and methods of the new page.
This way the code gets cleaner, easy to understand and also easy to maintain.
Hybrid Framework:
Hybrid Framework is a combination of more than one above mentioned frameworks. We will also use TestNG for setting up this framework. Once we are familiar with above three frameworks, Hybrid Framework will be easy to learn. We will do detailed analysis on this one too.
Behavior Driven Development:
Behavior Driven Development or BDD is the latest framework that is very popular with Agile methodology. Using this framework we will write test cases in easily readable and understandable format to Business Analysts, Developers, Testers, etc. We will use Cucumber to set up the framework and Gherkins language to write test cases in Cucumber.
So keep learning friends, many interesting topics to follow…
So far we learned about identifying and interacting with a single element in web page. What if we need to interact with multiple elements in a web page? Let’s modify our first test case and create a new one where we will interact with multiple web elements:
Second Test Case:
Navigate to “Google” website using Chrome Browser. Find the Search Web Element, enter a text “Selenium” and then do a search. Click on the second link which contains the text ‘Wikipedia’ and then verify the title of the web page displayed.
As you see that our requirement got changed. We need to click on the second link having with the text ‘Wikipedia’. So how do we overcome this problem?
One of the solution to this problem is to get a list of web elements using the ‘Partial Link Text‘ locator and store the elements in a List. From the List (Collections in JAVA), get the correct web element and then click on it to navigate to the required web page. Now let’s see how we can create a script in Selenium for our second test case.
package com.selenium.firstscript;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
public class FifthScript {
public static void main(String[] args) throws InterruptedException {
// Setting System properties
System.setProperty("webdriver.gecko.driver",
System.getProperty("user.dir") + "/Firefox/geckodriver");
// Initialize WebDriver
WebDriver driver = new FirefoxDriver();
// Navigate to Google Website
driver.get("http://www.google.com");
//Maximize browser window
driver.manage().window().maximize();
//Relative XPath for the text box
driver.findElement(By.xpath("//input[@id='lst-ib']")).sendKeys("selenium");
//Find the Web Element Search icon. After finding, click the search icon
driver.findElement(By.id("_fZl")).click();
//Wait for page to load. Thread.sleep() throws InterruptedException
Thread.sleep(3000);
//Locate all elements that contains the text Wikipedia and store them to a List
List listSelenium = driver.findElements(By.partialLinkText("Wikipedia"));
//verify the size of the List to confirm if the size is greater than 0
System.out.println("Size of listSelenium: "+listSelenium.size());
/*Now to get the second element from the List and click on it. Notice the index is 1 as the elements in a List starts with 0 index*/
listSelenium.get(1).click();
//Store the title in a variable
String title = driver.getTitle();
//Title verification. The third link is Wikipedia link
if (title.equals("Selenium (software) - Wikipedia")){
System.out.println("TITLE VERIFIED.");System.out.println("TEST CASE PASSED");
}
else
System.out.println("TITLE NOT VERIFIED.");
//Close and quit the driver to close the Browser
driver.close();
driver.quit();
}
}
Since we are expecting more than one elements to be returned, we have to use findElements in stead of findElement as displayed below.
//Locate all elements that starts with the text Selenium and store it in a List
List listSelenium = driver.findElements(By.partialLinkText("Wikipedia"));
The above code runs successfully in Eclipse and you can verify the results in the console.
Eclipse console output
With this we came to end on one of the biggest topics in Selenium testing. Keep on reading and I will update soon with new interesting topics. Till then, Happy Learning!
This is one of the biggest topic in Selenium Automation. Selenium Automation scripts executes by identifying the correct elements or objects (like textboxes, buttons, dropdowns etc.) in a web page and then by performing actions (like click, enter etc.) to them. If you are able to identify the elements preciously in a web page then your scripts becomes dependable and when executed they will be able to identify any changes to the captured elements.
There are numerous ways to identify the elements correctly. Not one method is better than the other as all these methods helps us in identifying the correct element.
Locating By ID:
Most of the elements in a web page have IDs but its always not necessary. Using IDs we can easily identify the elements in the web page as they are supposed to be unique.
If you refer to our last automation script that we created, there is a set of code that we used to identify the text box and search icon in Google website.
/*Find the Web Element Search Text Box. After finding the Web Element, enter the word "selenium"into the text box*/
driver.findElement(By.id("lst-ib")).sendKeys("selenium");
//Find the Web Element Search icon. After finding, click the search icon driver.findElement(By.id("_fZl")).click();
While referring to the above code you can see that we have used the text box ID as “lst-ib” and search icon ID as “_fZl” to identify the text box and search icon in the Google webpage.
While script creation, you can open the web page in any of the browsers and right click on the element and select ‘Inspect Element’. This will allow you to view the HTML code. From here you can get the ID attribute of the element. as mentioned its not necessary for the ID to be available. If its not there, then we have to look for other methods to identify the element.
ID = “lst-ib”
Locating By Name:
Like the ID attribute, name attribute can also be used for element identification. Names are unique most of the times, but it’s not always necessary. If not unique then it will identify the first element with the name attribute. Name locators are good to use for Forms having uniques name attributes.
//Code Sample for name locator
driver.findElement(By.name("q"));
Here for the Google text box, instead of ID, we can also use name attribute for element identification. The code will successfully identify the text box only if there is one name attribute with value ‘q‘.
Locating By Class Name:
You can locate a web element using class name also. Like the IDs, class name is also an attribute that can be present inside different html tags. Like in the above screenshot for the Google text box, there is an attribute class=”gsfi” also present along with ID and name attributes. We can use the below code sample to identify web elements using class names.
//Code Sample for name locator
driver.findElement(By.className("gsfi"));
The only problem with class names is that they are not unique like IDs. Same class names can be used for multiple web elements as a result it very hard to locate a web element using class names only.
Locating By Link Text:
Link Text locators are applicable to hyperlink texts. Its used to locate the text inside anchor tags in html. Like in our last script, after clicking the search icon, Google displays list of website links. Our scripts searches for the link which has a text “Selenium – Web Browser Automation”. Of course it finds the link and clicks on it but how did it identify?
Link Text “Selenium – Web Browser A…”
We can use the below code sample to identify web elements using Link Text.
//Find the first link displayed using the link text and click the link
driver.findElement(By.linkText("Selenium - Web Browser Automation")).click();
Link Text is best to identify the hyperlinks in web page.
Locating By Partial Link Text:
Partial Link Text is almost same as Link Text. The only difference is that you don’t have to mention complete text in order to find the hyperlink. You can just mention partial text. However you need to make sure that the partial text is unique otherwise it will locate the first element from the list. We can use the below code sample to identify web elements using Link Text.
//Find the first link displayed using the link text and click the link
driver.findElement(By.partialLinkText("Selenium - ")).click();
Locating By Tag Name:
Tag Name can also be used in identifying the web elements. However finding web elements using Tag Names aren’t much popular as there are better methods to identify the elements. Like for example if the web page has only one drop down, you can use the Tag Name to locate the html tag “select”. We can use the below code sample to identify web elements using Tag Name.
//Find the first link displayed using the link text and click the link
driver.findElement(By.tagName("select"));
Locating By CSS Selector:
CSS Selector is one of the faster ways to identify a web element. There are different ways by which we can use the the CSS Selectors to locate a web element. Lets take multiple instances of Google text box. We will use CSS Selector in multiple ways to locate the text box. Refer the screenshot for easy understanding.
input tag of Google text box
Using ID only:
//css selectors using ID
driver.findElement(By.cssSelector("input#lst-ib")).sendKeys("selenium");
Please note for ID attribute we need to use ‘#’
Using Class Name only:
//css selectors using class name
driver.findElement(By.cssSelector("input.gsfi")).sendKeys("selenium");
Please note for class name attribute we need to use ‘.’
Using any one of the attributes:
//css selectors using name attribute
driver.findElement(By.cssSelector("input[name='q']")).sendKeys("selenium");
Please note that for any attributes we can use the above code in the format “element_name[<attribute_name>=‘value’]”. Like the name attribute there are other attributes present in the ‘input‘ tag which we can use to find the text box.
Using more that one attribute:
//css selectors using more than one attributes
driver.findElement(By.cssSelector("input[name='q'][role='combobox']")).sendKeys("selenium");
Please note if we need to use more than one attributes to identify a web element, we can use the above code in the format “element_name[<attribute_name>=‘value’][<attribute_name>=‘value’]”.
If we need to access to an element inside the unordered list (inside the ul tag), we can use the following example.
Selenium web site with tabs under unordered list (ul)
We can identify any of the listed item (li tag) inside the unordered list (ul) using the “nth-of-type” in the CSS Selector.
//css selector for clicking the first listed item in unordered list
driver.findElement(By.cssSelector("ul li:nth-of-type(1)")).click();
Using css selectors for random attributes:
Sometimes attributes like IDs are not constant. They keep on changing with every session. Like the case of below screenshot where you can notice the value of ID is a combination of alphanumerical. Sometimes the numerical value changes with each session. In that case we can consider only partial value of an attribute.
IDs are not constant
For random attributes, we can use different ways like ‘starts with’, ‘ends with’, ‘contains’ in the CSS Selector to identify the web element. Let’s assume the attribute values of the ‘Sign in’ button in the above screenshot keeps changing with every new session. We will use different methods to identify the ‘Sign in’ button.
//css selector where id starts with 'uh-sign'
driver.findElement(By.cssSelector("a[id^='uh-sign']")).click();
Please note we have to use ‘^=‘ for attributes ‘start with’
//css selector where id ends with 'signin'
driver.findElement(By.cssSelector("a[id$='id$='signin']")).click();
Please note we have to use ‘$=‘ for attributes ‘ends with’
//css selector where id has sub string or contains 'h-sign'
driver.findElement(By.cssSelector("a[id*='h-sign']")).click();
Please note we have to use ‘*=‘ for attributes ‘sub string’
Above were the most commonly used CSS Selectors, however you can still play around with CSS Selectors for identifying the elements. Please visit the below URL for more information:
XPath locator is one of the most used locators for finding elements in a web page. XPath is defined as XML Path and it locates an element by traversing between various elements across the entire page and thus finding the desired element with reference to another elements. There are many free plugins available for the browsers using which we can get an XPath of an element. ‘Firebug’ and ‘Firepath’ are most commonly used add ons for Firefox browser and ‘XPath Helper’ for Chrome browser. Here I will be using the add ons from Firefox browser to view the XPath.
There are two types of XPaths:
Absolute XPath:
Absolute XPath begins from the root path with a single forward slash(/) and followed by complete path of the web element. For example in Google web page, the Absolute XPath for the text box is ‘html/body/div/div[3]/form/div[2]/div[2]/div[1]/div[1]/div[3]/div/div/div[3]/div/input[1]’
FirePath add-on in Firefox browser
As you see Absolute XPath is the complete path starting from the root of the web page to the actual element. The code for Absolute XPath will be:
//Absolute XPath for the text box
driver.findElement(By.xpath("/html/body/div/div[3]/form/div[2]/div[2]/div[1]/div[1]/div[3]/div/div/div[3]/div/input[1]")).sendKeys("selenium");
However there is one big disadvantage in using Absolute XPath locators. There is a high possibility of failure even if small changes are made to the reference elements. Due to this sole reason Absolute XPaths are seldom used.
Relative XPath:
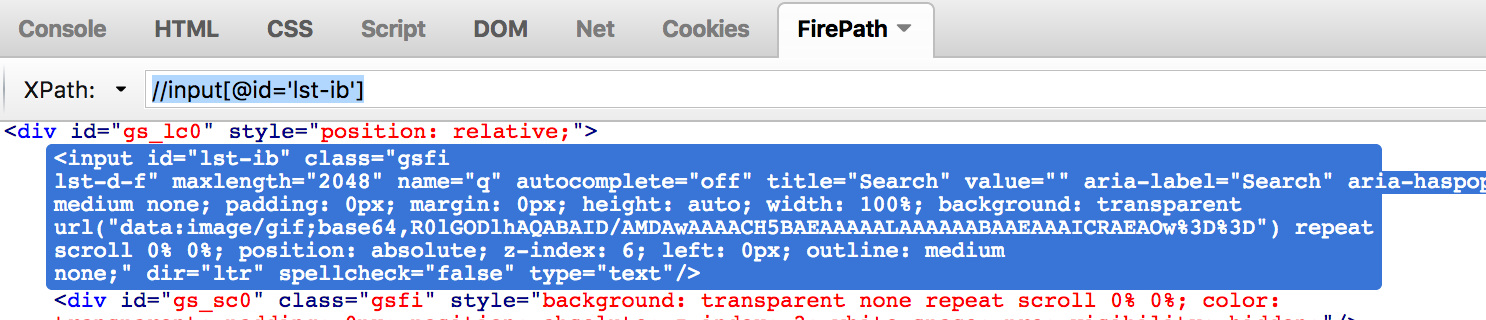
Relative XPath starts from the middle of the HTML DOM structure. Its start with the double forward slash (//), which means it can search the element anywhere at the web page. For example the same Google text box can have the Relative XPath as displayed below:
FirePath add on to find Relative XPath
The code for Relative XPath will be:
//Relative XPath for the text box
driver.findElement(By.xpath(".//*[@id='lst-ib']")).sendKeys("selenium");
As you can see Relative XPath does not uses the complete path, rather it starts in the middle of the web page. ‘.//*[@id=’lst-ib’]‘ means to search for the ID relative to the current node reference.
The same XPath code can be written in a much better way:
//Relative XPath for the text box
driver.findElement(By.xpath("//input[@id='lst-ib']")).sendKeys("selenium");
You can use any of the attributes of the element in this code but make sure to use ‘@‘ in front of the attribute. By replacing ‘*‘ with ‘input‘ tag, we are specifically instructing the driver to search for the ID in ‘input‘ tag only otherwise it will look for the ID in all tags.
Some more examples for identifying Google text box using Relative XPath:
XPath for Google text box
//Xpath of text box with Class attribute
driver.findElement(By.xpath("//input[@class='gsfi']")).sendKeys("selenium");
//Xpath of text box with Name attribute
driver.findElement(By.xpath("//input[@name='q']")).sendKeys("selenium");
Relative XPath using contains():
When the partial value of an attribute is dynamic, we can use contains() method in Relative XPath to locate the web element. The same code for identifying the Google text box can be written using contains() method:
//Xpath of text box with Class attribute using contains() method
driver.findElement(By.xpath("//input[contains(@class,'gsfi')]")).sendKeys("selenium");
//Xpath of text box with Name attribute using contains() method
driver.findElement(By.xpath("//input[contains(@name,'q')]")).sendKeys("selenium");
Please note that we need to be careful when using the contains() method as it will try to locate all elements which contains the value that we mentioned in the code.
We can also use the contains() method to locate an element using text.
XPath locator for Sign in
In the above screenshot of Yahoo web site, we can locate the text ‘Sign in’ using contains() method.
//XPath of Sign in button using contains() method
//Locating using text
driver.findElement(By.xpath("//a[contains(text(),'Sign')]"));
Relative XPath using starts-with():
Like contains() method, starts-with() method can be used for elements with dynamic values. The same code for locating the Sign in button in Yahoo web site can be written using starts-with() method:
//XPath of Sign in button using starts-with() method
//Locating using ID
driver.findElement(By.xpath("//a[starts-with(@id,'uh-sign')]"));
Similar to contains() method, starts-with() method can be used for other attributes and text(). The same code can be written locating the web element using text():
//XPath of Sign in button using starts-with() method
//Locating using text
driver.findElement(By.xpath("//a[starts-with(text(),'Sign')]"));
Relative XPath using OR & AND:
OR expression can be used when any one or all conditions are met. The same code for Sign in can be written as:
//XPath of Sign in button using OR conditions
driver.findElement(By.xpath("//a[@id='uh-signin' OR @class='xxx']"));
In the above case the driver successfully locates the Sign in button as one of the condition is met.
The same code fails when we use AND expression as there is no class attribute in anchor tag with value ‘xxx’
//XPath of Sign in button using AND conditions
//Code fails to locate the Sign in button
driver.findElement(By.xpath("//a[@id='uh-signin' AND @class='xxx']"));
Relative XPath using axes methods:
Sometimes when locating a web element becomes extremely difficult when they don’t have any fixed attributes. In that case we can use the help of different axes methods to navigate to correct element.
Following method can be best explained by this example:
XPath locator using following
In this example we are first locating ‘input‘ tag with ‘id=lst-ib’ and then using this as reference we will list out all ‘input‘ tags following the first located ‘input‘ tag. Always remember that following will list out all tags. However in this case you can locate a specific ‘input‘ by adding an index. Code sample for following:
//XPath Locator using following method
driver.findElement(By.xpath("//input[@id='lst-ib']/following::input[1]"));
Here we are first locating the ‘input‘ tag with ‘id=lst-ib’ and then using this ‘input‘ tag as reference, locate all other ‘input‘ tags in downward direction using following command. And then navigating to first ‘input‘ tag using ‘[1]‘ in our code.
2. Preceding works the same way. Only difference, instead of navigating in forward direction it travels in reverse direction. The code using Preceding can be written as:
//XPath Locator using preceding method
driver.findElement(By.xpath("//input[@id='gs_htif0']/preceding::input[1]"));
In the above example we are first locating the ‘input‘ tag with ‘id=gs_htif0’ and then using this ‘input‘ tag as reference, locate all ‘input‘ tags in upward direction using preceding command. And then navigating to first ‘input‘ tag using ‘[1]‘ in our code.
3. The ancestor axis selects all ancestors element (grandparent, parent, etc.) of the current node as displayed below:
XPath locator using ancestor
In the above example, we are first locating one child ‘div‘ tag using ‘id=mega-bottombar’ and then using it as reference, locate all the ‘div‘ ancestors for the ‘div‘ tag.
Code sample for the ancestor method:
//XPath using ancestor method
driver.findElement(By.xpath("//div[@id='mega-bottombar']/ancestor::div"));
4. The Child axis works similarly as ancestor method but in the opposite direction.
XPath using child
In the above example we are first locating the ancestor ‘div‘ with ‘id=mega-uh-wrapper’and then using it as a reference, list out all the child ‘div‘ tags. Code sample for this example:
//XPath using child method
driver.findElement(By.xpath("//div[@id='mega-uh-wrapper']/child::div"));
5. Following-sibling method is used to identify all the siblings at the same level of the current node.
XPath using following-sibling
In this example we are first locating the ‘div‘ element with ‘id=mega-topbar’ and then using it as reference, locate all other ‘div‘ tags which are siblings and are following to the located ‘div‘ tag. Code sample for this example:
//XPath using following-sibling method
driver.findElement(By.xpath("//div[@id='mega-topbar']/following-sibling::div"));
6. Preceding-sibling just works in the opposite direction of following-sibling. Instead of moving into forward direction, it moves in a reverse direction.
XPath using preceding-sibling
In this example we are first locating the ‘div‘ tag with ‘id=mega-bottombar’ and then using it as reference, locate all other ‘div‘ tags which are siblings and are preceding to the located ‘div‘. Code sample for this example:
//XPath using preceding-sibling method
driver.findElement(By.xpath("//div[@id='mega-bottombar']/preceding-sibling::div"));
7. Using parent method we can locate the parent of the current node.
In this example we are first locating the ‘div‘ tag with ‘id=mega-bottombar’ and then using it as reference, locate the parent ‘div‘ tag with ‘id=mega-uh-wrapper‘. Code sample for this example:
//XPath using parent method
driver.findElement(By.xpath("//div[@id='mega-bottombar']/parent::div"));
8. Using descendant method we can select all the descendants of the current node.
XPath locator using descendant
In this example we are first locating the ‘td‘ tag with ‘id=yui_3_18_0_4_1488151541532_940’ and then using it as reference, list out all the descendants having ‘input‘ tags. Code sample for this example:
//XPath using parent method
driver.findElement(By.xpath("//td[@id='yui_3_18_0_4_1488151541532_940']/descendant::input"));
With this we came to an end to the first part of Element Locators. Although the topic was lengthy, its also an important one. I would suggest to try out each of the Element Locator in Eclipse so that you can clearly understand the way Selenium identifies the elements in a web page.
Additional Note:
What is the difference between following and following-sibling?
The below two links will help you understand the difference between following and following-sibling.
Selenium scripts work with multiple browsers. In our first script we used Chrome browser and for executing the script in Chrome browser we had to set properties for Chrome Driver. In this post I will be mainly focusing on setting properties for other browsers. Before working with different browsers, make sure the browsers are installed on your machine. This is a prerequisite for executing the script in different browsers.
Safari:
Safari browser now provides native support for the WebDriver API. This means that you don’t have to download the Safari driver from third party section like we did for Chrome browser. Just change the System Properties as mentioned below and the scripts works just fine in Safari. You can copy the code from ‘FirstScript’ in ‘com.selenium.firstscript’ package and paste the script in a new class file ‘SecondScript’. Change the System properties and driver information as displayed below.
Safari Driver
Firefox:
With Selenium 3, for executing the scripts in Firefox browser, we will have to download the GeckoDriver. You can go to Selenium Website, go to Downloads, and then to ‘Third Party Drivers, Bindings, and Plugins’ section. Click the ‘Mozilla GeckoDriver’ link to go to download page.
Once you reach the GeckoDriver page, download the latest driver package based on your Windows/Mac OS to your local folder. Follow the same step for Chrome Browser download i.e. create a new folder ‘Firefox’ inside your root directory of the Java project that we created earlier. Copy the downloaded executable file into the ‘Firefox’ folder. Once done, create a new class file called ‘ThirdScript’ and copy paste the code from ‘FirstScript’ or ‘SecondScript’ file. Now we have to update the System properties and the driver information in the ‘ThirdScript.java’ file as mentioned below.
Firefox Driver
IE:
You need to download the MS Edge driver from the Selenium website and repeat the same steps of Chrome/Firefox browsers. The only difference is on the below code. Use these codes for IE browser:
System.setProperty("webdriver.ie.driver", "System.getProperty("user.dir") + "/IE/IEdriver"");
WebDriver driver = new InternetExplorerDriver();
Please note for Window OS, always use ‘\\’ instead of ‘/’ for setting the driver to correct location.
Note: When using MAC, to make the Driver executable, we have to run below command in Terminal where the driver is placed: chmod +x chromedriver
Now that we have set the System properties and created the driver object, the next task is to complete the remaining steps of our test case using the driver object.
I am attaching the complete code of our test case. I have added comments for each code for easy understanding.
Complete code for our Test Case
As we execute this script by clicking Run As -> Java Application, we will see the below message in our Eclipse console.
Test Case Passed
Additional Information:
What are System Properties?
The System class maintains a set of properties in key/value pairs that define traits or attributes of the current working environment. When the runtime system first starts up, the system properties are initialized to contain information about the runtime environment including information about the current user, the current version of the Java runtime, and even the character used to separate components of a filename. One of the example of the System Properties is “user.dir” that we used in the above program. “user.dir” refers to User’s current working directory and this property is already set in properties. Same way we are to manually set the System Property of Chrome browser “web driver.chrome.driver” which actually refers to the location of executable file.
What are element locators?
Selenium uses element locators to find the elements in the Web Page. In the above script, we used element locators like ID, LinkText etc to check if the element is present in the page. If the elements are present then we will be performing certain actions like ‘Click’ or ‘SendKeys’ using the driver object. If elements are not there or found then NoSuchElementException will be thrown and the script will fail. As we proceed further I will provide detailed explanation on different types of element locators and how to identify the correct locators while creating our scripts.
So far we wrote our first Selenium Script by creating a WebDriver object. Now by using this object we will navigate to a website and then perform various validations.
Our First Test Case:
Navigate to “Google” website using Chrome Browser. Find the Search Web Element, enter a text “Selenium” and then do a search. Click on the first link displayed and verify the title of the page after loading the web page. This is a manual test case that we will try to automate.
Let resume from our FirstScript.java that we created in last post. Add a new code “driver.get(http://www.google.com)” and save the script.
To execute the script, right click FirstScript.java and click Run As -> Java Application. The moment we execute this script, we get an exception in the IDE Console. The error says “The path to the driver executable must be set by the webdriver.chrome.driver system property”. This means that we have to inform the System or JVM the path of Chrome driver executable file by setting the system property.
Exception
Setting up System Property:
Windows OS/Mac OS:
To keep the script organized, you can create a new folder called “Chrome”inside our Java Project. This can be done easily by right clicking “FirstSeleniumProject” and then selecting New -> Folder.
Create a folder
Place the downloaded Chrome Driver Executable file (the one we downloaded in the last post) in this folder. We can do this by simply drag and drop from the Download folder. The above two steps can be avoided, however I did this just to make our script organized.
The next step is to set the System Properties for “webdriver.chrome.driver” with the location of the Chrome Driver executable file that we downloaded in the last post. Always remember, that this setting need to be done before assigning the WebDriver.
For Window OS – Add the following code for setting System Property for Chrome Driver
Code Snapshot for setting System Property for Chrome Driver
To make the driver object to navigate to a Google website, use the following code ‘driver.get(http://www.google.com)’. Always make sure to use the complete path of the URL including the http protocol.
Save the code and execute the script by clicking Run As -> Java Application or else you can also use the green play icon displayed in the header of Eclipse.
Click the green play button to execute the script
Once the execution starts, you will be able to see Google website opens in a new Chrome Browser window.
Google website opens in Chrome browser
And this completes the first step of our test case.